Methods · Sub-page
Self-supervised audio — learning without labels.
The trick that made bioacoustics tractable at scale: stop telling the model what to look for, and let it discover what distinguishes any clip from any other.
AI narration · Methods · Self-supervised audio
Self-supervised learning is the trick that made bioacoustics catch up to vision and language. Instead of training a model on hand-labeled data — which is expensive and scarce in the wildlife world — you train it on millions of unlabeled recordings using a pretext task: predict the masked-out portion of the audio, or recognize when two clips come from the same source. The model learns rich representations without anyone telling it what a crow sounds like. Stefan Kahl's BirdNET work and the Earth Species Project's NatureLM-audio both descend from this paradigm. The downstream effect: a 1,024-dimensional vector that captures more about a vocalization than any hand-engineered feature ever could.
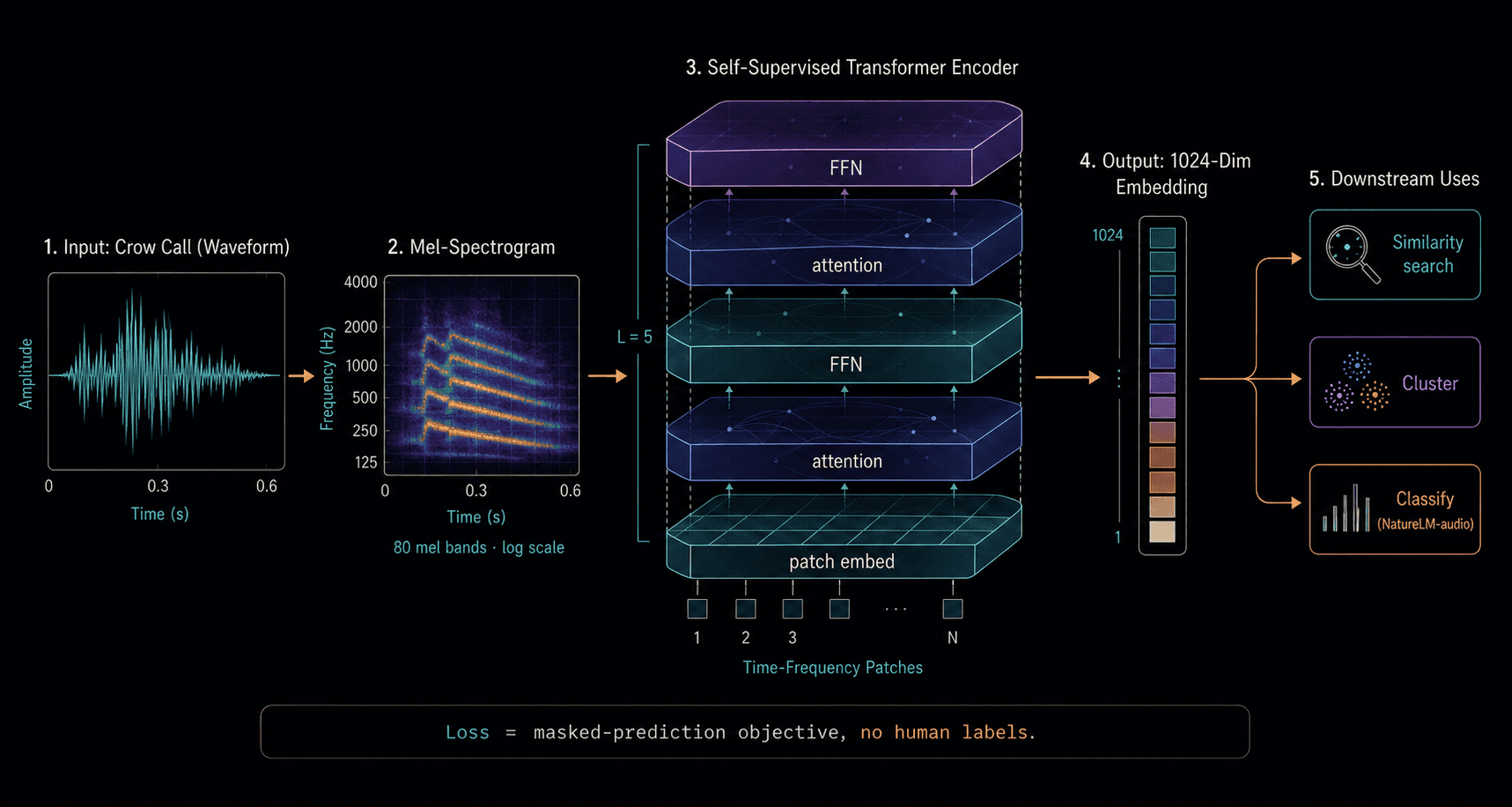
The setup
Take a transformer architecture designed for sequences. Feed it the mel-spectrogram of an audio clip, broken into patches along the time-frequency grid. Randomly mask 30–80% of those patches. Ask the model to reconstruct the missing patches from the visible ones. The loss is the reconstruction error; the supervision is the audio itself.
No human ever labels a clip. The model is forced to learn representations of audio that are rich enough to predict masked regions from context — which means rich enough to represent acoustic structure, harmonic relationships, temporal dynamics, and (for bioacoustic models) species- and individual-specific timbre.
What the model actually learns
The hidden layers of a well-trained audio model carry features at multiple scales: low-level spectral templates in early layers, harmonic relationships in the middle, and call-type-like abstractions in the late layers. Pulling out the late-layer activations gives an you can use for similarity, clustering, or classification — with no further training needed.
The same model, frozen, can answer many downstream questions: is this a crow at all (vs. a jay)? How similar is this caw to that one? Which of these clips belongs to the same individual? That transferability is what makes the "foundation" framing apt.
Why it works for bioacoustics
Bioacoustic data has two properties that make SSL especially effective: it's plentiful and it's costly to label. Decades of unlabeled field recordings sit in archives; expert annotation is slow and expensive. SSL flips the economics — the labels you do have become evaluation, not training.
One sentence of math
For a sequence of patches x = (x₁, …, xₙ), the model minimizes the reconstruction error L = Σᵢ∈M ‖ f(x_\M) − xᵢ ‖² where M is the masked subset and fis the transformer's output for the masked positions given the visible context.
What it doesn't learn
SSL learns acoustic structure, not meaning. A vector cluster corresponds to acoustic similarity, not to a behavioral function. To connect cluster to context — what the call does — you still need synchronized behavioral observation. That join happens at stage 6 of the pipeline, not inside the model.
We didn't need to know what the model would learn. We just needed enough data, the right loss, and the patience to look at what came out the other side.