Decoding · Flagship
What we can decode now.
AI narration · Decoding · What we can decode now
What's new isn't any single feature — researchers have been measuring pitch contour and harmonic emphasis in crow caws for decades. What's new is that we can extract all of them simultaneously, automatically, on millions of calls, and locate each call as a single point in a shared map where similarity is geometry. Sex, identity, behavioral context, individual signature, location-specific dialect — every one of these dimensions becomes a queryable property of the latent space. The territorial caw cluster differs from the mobbing caw cluster not by one variable but by a thousand correlated micro-differences, all recoverable in a forward pass.
A single caw is not a single thing. Pulled apart by a self-supervised model, a half-second of crow voice splits into measurable layers, each carrying different information.
Pitch contour is the most reliable sex tag — female caws sit, on average, slightly higher and with a steeper terminal fall. Harmonic emphasis — which overtones are loud relative to the fundamental — fingerprints the individual, the way a human voice has timbre independent of pitch. Duration and inter-call interval shift with context: territorial caws are slower and more evenly spaced than mobbing caws, which compress and pile up. And the spectral grain — the noisy, raspy quality that researchers since the 1970s called “harshness” — tracks something like arousal.
What's new is not that any one of these dimensions exists. Researchers documented sex- and identity-encoded features in crow caws over a decade ago. What's new is that we can now extract all of them simultaneously, automatically, on millions of calls, and locate each call as a single point in a shared map where similarity is geometry.
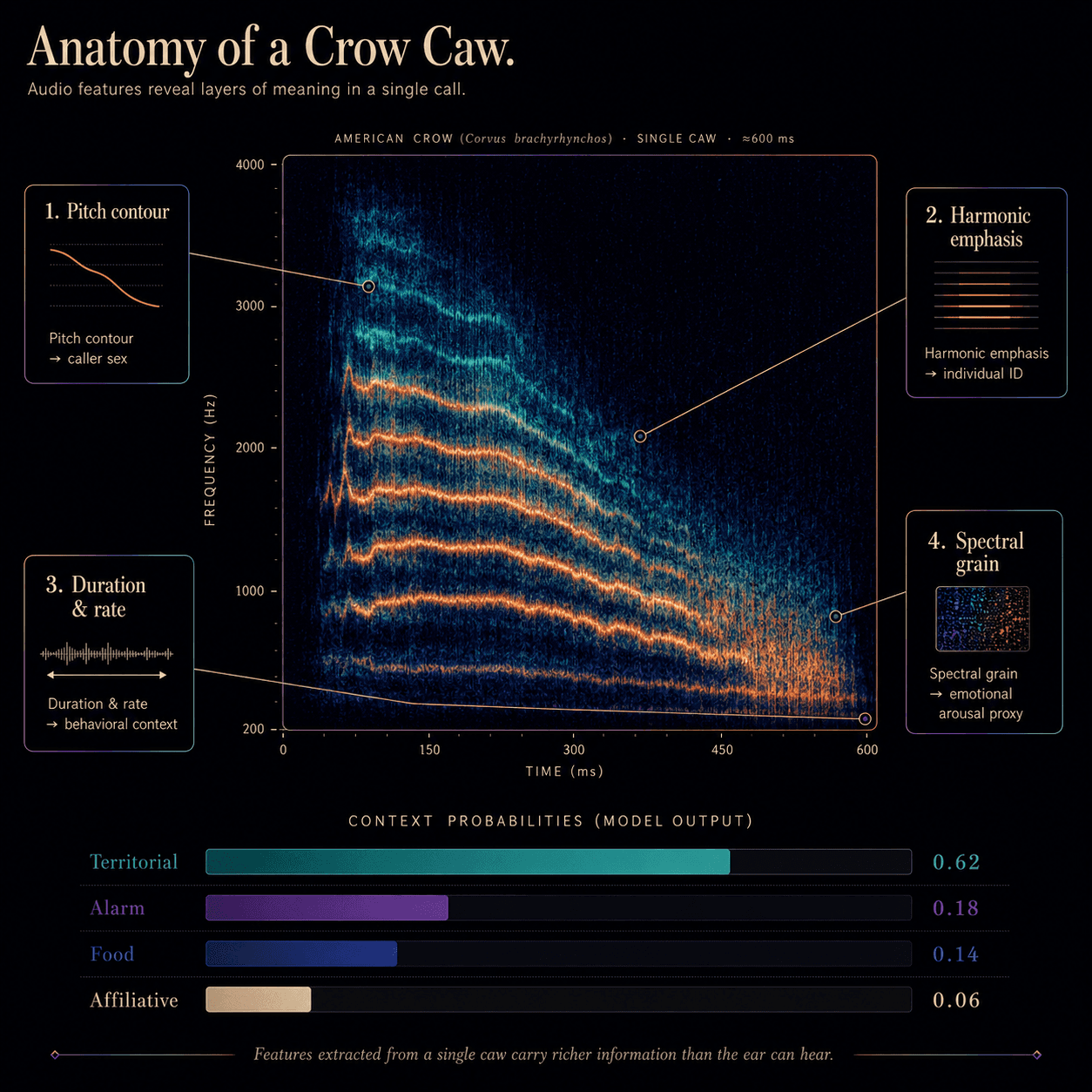
▸ Show underlying data
- Territorial
- 0.62
- Alarm
- 0.18
- Food
- 0.14
- Affiliative
- 0.06
The practical consequence: when a crow caws, a model trained on enough crow audio can, in milliseconds, tell you that it is a crow, probably which crow, probably its sex, the most likely behavioral context, and how acoustically typical or unusual the call is relative to that crow's own history. None of those is “translation” in the strong sense. All of them used to take a graduate student a week.
The frontier — the part we have not crossed — is composition. Does the order in which a crow strings caws and rattles together carry meaning beyond the sum of its parts? . Behavioral evidence is suggestive but thin. This is where the next five years live.